
需求和分析
近期应领导要求做了一个内部使用的知识库系统,用于收藏文章、网页和文档等。除了管理功能,新增加了直接在线阅读上传的文件的功能。
首先,上传的文件格式肯定是不统一的,主要需要考虑word、Excel、PPT和PDF等这些常用的文件。office文件可能是因为微软的版权(个人猜测)或其他原因是不好直接利用JS打开阅读的。搜索了一番,PDF文件时可以直接使用开源的相关js框架直接打开的。
所以第一步是将office文件转为PDF文件,之后使用相关js技术展示PDF文件。
实现
经过一番尝试,系统共使用了下列插件或框架。
- openOffice
- PDFjs
- PDFh5
openOffice也可以使用LibOffice代替,不过没试过
PDFh5是基于PDFjs的为移动端做的框架。PDFjs是直接展示的PDF文件,但是在某些浏览器上无法使用,点名微信内部的x5垃圾浏览器(系统主要使用场景就是在微信内打开)和小米自带的浏览器,都无法加载PDF文件。为了解决这个问题,就找到了PDFh5,它的原理其实就是又加了一步转换,将PDF渲染成图片,然后在移动端展示,作者也已经支持了双指缩放。缺点就是当文件比较大的时候,缩放会特别的卡顿。
OpenOffice
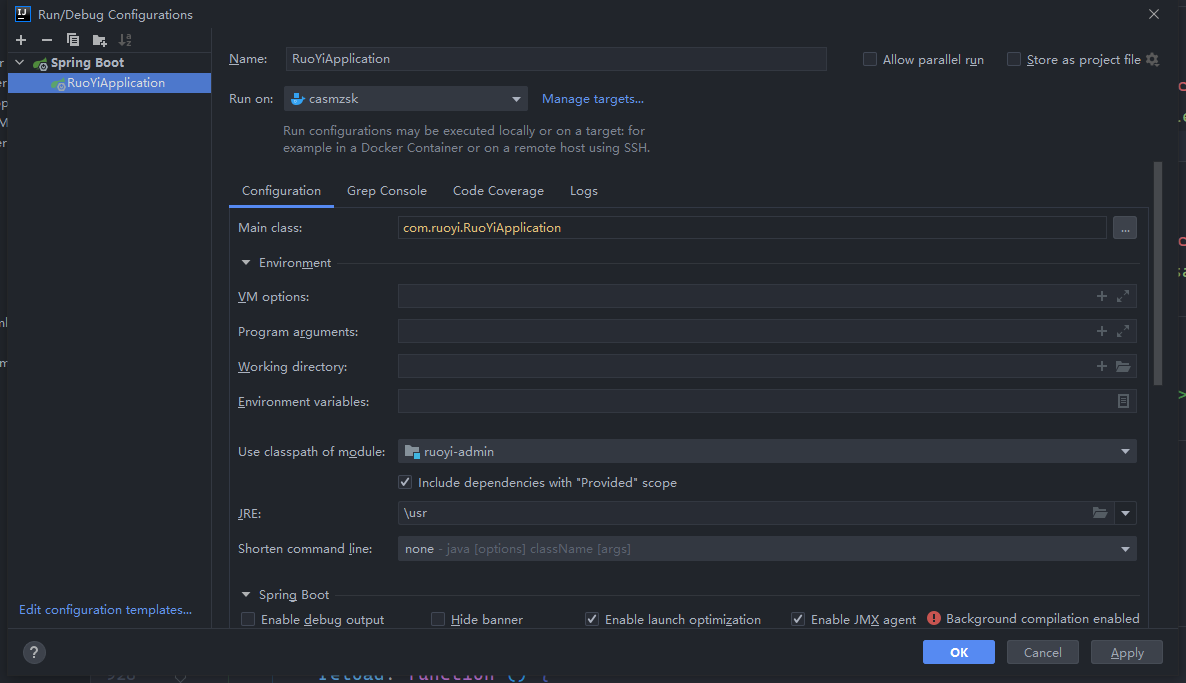
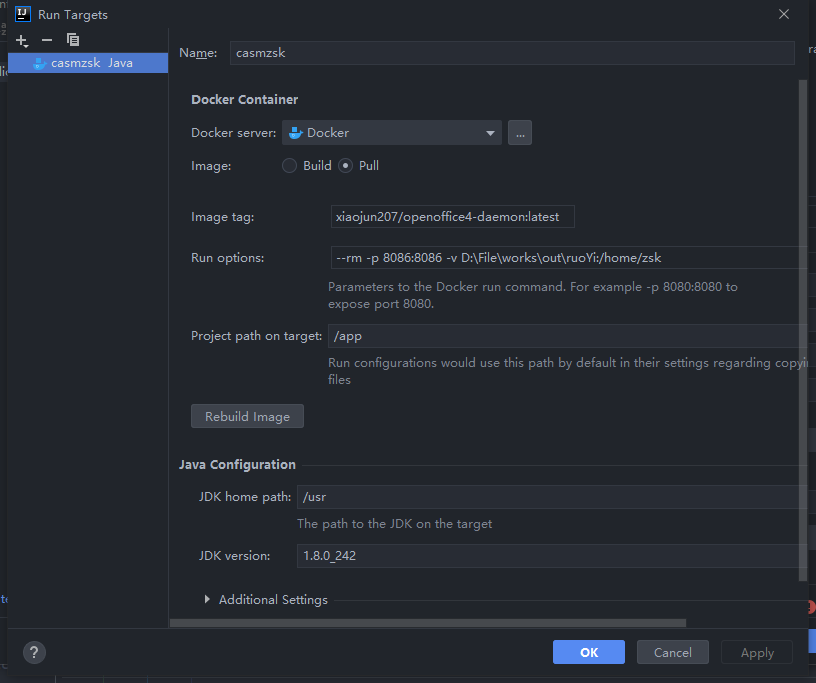
由于不想在电脑上安装软件,而且服务器上也不好随便安装软件,所以采用的是Docker的方式,将系统与镜像运行在同一容器下。
OpenOffice镜像使用的是 xiaojun207/openoffice4-daemon ,将其作为基础镜像,然后将jar包打包进去。
Dockerfile如下
# Docker image for springboot file run
# VERSION 0.0.1
# Author: eangulee
# 基础镜像使用java
FROM xiaojun207/openoffice4-daemon:latest
# 作者
MAINTAINER xgblack <gmg@xgblack.cn>
# VOLUME 指定了临时文件目录为/tmp。
# 其效果是在主机 /var/lib/docker 目录下创建了一个临时文件,并链接到容器的/tmp
VOLUME /tmp
USER root
# 将jar包添加到容器中并更名为app.jar
ADD casmzsk.jar app.jar
# 运行jar包
RUN bash -c 'touch ./app.jar'
ENTRYPOINT ["java","-Djava.security.egd=file:/dev/./urandom","-jar","./app.jar"]其中USER root是将用户切换为root,应该不需要,但是懒得改了
然后正常使用docker build docker run 打包和运行了。
另外,赞一下IDEA2021.1,支持直接运行到docker。
在pom.xml文件中引入以下依赖:
<!--jodconverter 核心包 -->
<!-- https://mvnrepository.com/artifact/org.jodconverter/jodconverter-core -->
<dependency>
<groupId>org.jodconverter</groupId>
<artifactId>jodconverter-core</artifactId>
<version>4.4.2</version>
</dependency>
<!--springboot支持包,里面包括了自动配置类 -->
<!-- https://mvnrepository.com/artifact/org.jodconverter/jodconverter-spring-boot-starter -->
<dependency>
<groupId>org.jodconverter</groupId>
<artifactId>jodconverter-spring-boot-starter</artifactId>
<version>4.4.2</version>
</dependency>
<!--jodconverter 本地支持包 -->
<!-- https://mvnrepository.com/artifact/org.jodconverter/jodconverter-local -->
<dependency>
<groupId>org.jodconverter</groupId>
<artifactId>jodconverter-local</artifactId>
<version>4.4.2</version>
</dependency>文件转为PDF:
/**
* 将文件转为pdf
* @param path
* @return
* @throws OfficeException
*/
private String convertFileToPdf(String path) throws OfficeException {
File file = new File(path);
String pdfPath = RuoYiConfig.getPdfFile();
if (!pdfPath.endsWith("/")) {
pdfPath += "/";
}
//转换之后文件生成的地址
File newFile = new File(pdfPath);
if (!newFile.exists()) {
newFile.mkdirs();
}
String fileName="CasmZsk_"+ UUID.randomUUID().toString().replaceAll("-","");
//pdf文件后缀
String fileType=".pdf";
//将这三个拼接起来,就是我们最后生成文件保存的完整访问路径了
String newFileMix = pdfPath + fileName + fileType;
//文件转化
converter.convert(file).to(new File(newFileMix)).execute();
return Constants.RESOURCE_PDF_PREFIX + "/" + fileName + fileType;
}
PDFjs
使用的方式有很多,本文只讲述系统采用的方法,只是为了快速出效果,所以没有仔细研究。
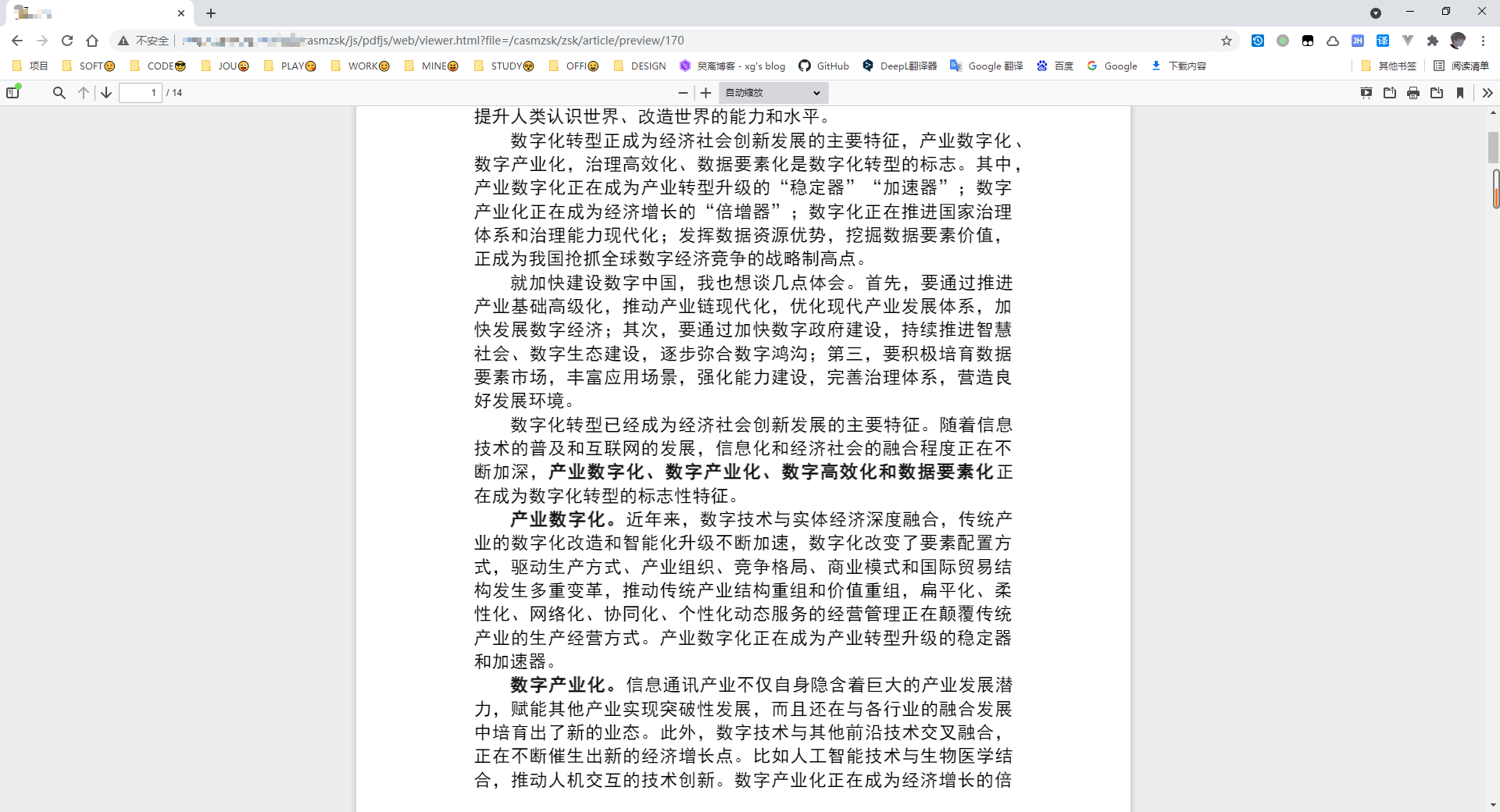
后台提供一个将文件读取为文件流返回的接口,然后跳转到PDFjs内的viewer.html文件,?file=参数后面拼接上后端的接口
例如http://localhost:8080/casmzsk/js/pdfjs/web/viewer.html?file=/casmzsk/article/preview/170
170是通过JS动态拼接的文件的id,可以使用其他的标识来指定文件,只要后端能接收并找到文件即可,效果如下,此种方式由于是直接打开的PDF,所以是可以复制文字的。
接口:
@GetMapping("/preview/{articleId}")
public void pdfStreamHandler(@PathVariable Integer articleId,HttpServletRequest request, HttpServletResponse response) {
//PDF文件地址
PdfConverter pdf = pdfConverterService.selectByArticleId(articleId);
if (pdf == null) {
//重新生成
Article article = articleService.selectArticleById(articleId);
String path = article.getArticlePath();
String pdfMd5 = Md5Utils.hash(path);
path = path.replace(Constants.RESOURCE_PREFIX, RuoYiConfig.getProfile());
String pdfFile = null;
try {
pdfFile = convertFileToPdf(path);
//保存
pdf = new PdfConverter();
pdf.setArticlePath(pdfMd5);
pdf.setPdfPath(pdfFile);
pdf.setConvertFlag(1);
pdfConverterService.insertSelective(pdf);
} catch (OfficeException e) {
logger.error("pdf转换出错");
e.printStackTrace();
}
}
String pdfPath = pdf.getPdfPath();
pdfPath = pdfPath.replace(Constants.RESOURCE_PDF_PREFIX, RuoYiConfig.getPdfFile());
File file = new File(pdfPath);
if (file.exists()) {
byte[] data = null;
FileInputStream input=null;
try {
input= new FileInputStream(file);
data = new byte[input.available()];
input.read(data);
response.getOutputStream().write(data);
logger.info(">>> pdf文件预览:" + pdfPath);
} catch (Exception e) {
logger.error("pdf文件处理异常:" + e);
}finally{
try {
if(input!=null){
input.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
PDFh5
可以去GitHub上看简介和使用,使用方法写的挺详细的 https://github.com/gjTool/pdfh5
http://localhost:8080/casmzsk/reader/170
新建一个空白页面,写一个指定id的div,页面加载时使用ajax发送请求,并接收返回的数据
$.ajax({
url: ctx + "/zsk/article/pdfStream/" + articleId,
type: "get",
dataType : "json",
mimeType: 'text/plain; charset=x-user-defined',//jq ajax请求文件流的方式
success: function (data) {
if (data.code >= 0) {
var pdfh5 = new Pdfh5('#demo', {
pdfurl: "data:application/pdf;base64," + data.data,
});
} else {
$.modal.msgError("文件读取错误");
}
}
});@GetMapping("/pdfStream/{articleId}")
@ResponseBody
public AjaxResult getPpdfStream(@PathVariable Integer articleId,HttpServletRequest request, HttpServletResponse response) {
//PDF文件地址
PdfConverter pdf = pdfConverterService.selectByArticleId(articleId);
if (pdf == null) {
//重新生成
Article article = articleService.selectArticleById(articleId);
String path = article.getArticlePath();
String pdfMd5 = Md5Utils.hash(path);
path = path.replace(Constants.RESOURCE_PREFIX, RuoYiConfig.getProfile());
String pdfFile = null;
try {
pdfFile = convertFileToPdf(path);
//保存
pdf = new PdfConverter();
pdf.setArticlePath(pdfMd5);
pdf.setPdfPath(pdfFile);
pdf.setConvertFlag(1);
pdfConverterService.insertSelective(pdf);
} catch (OfficeException e) {
logger.error("pdf转换出错");
e.printStackTrace();
}
}
String pdfPath = pdf.getPdfPath();
pdfPath = pdfPath.replace(Constants.RESOURCE_PDF_PREFIX, RuoYiConfig.getPdfFile());
File file = new File(pdfPath);
if (file.exists()) {
byte[] data = null;
FileInputStream input=null;
try {
input= new FileInputStream(file);
data = new byte[input.available()];
input.read(data);
//response.getOutputStream().write(data);
logger.info(">>> pdf文件预览:" + pdfPath);
} catch (Exception e) {
logger.error("pdf文件处理异常:" + e);
}finally{
try {
if(input!=null){
input.close();
}
} catch (IOException e) {
e.printStackTrace();
return AjaxResult.error();
}
}
return AjaxResult.success(data);
}
return AjaxResult.error();
}
拼接文件阅读链接的时候,判断一下设备是桌面端还是移动端,然后拼接不同的链接就可以了。
后记
文章贴的代码是直接从系统中复制的,还有一些业务判断等的代码,不再整理了。
希望大家每天都有进步,加油吧
















































主要是想单独起一个office转换来提供服务,因为业务服务更新很频繁,如果把office转换和业务服务放在同个镜像里,每次构建耗时就太长了
我最初也是想单独起一个服务,但是分开的话,应用会找不到 office,急着交差没有仔细研究就放一起去了。可以加个微信交流一下 微信号gmg8gmg
博主你好~我在网上搜了半天找到了你这个博客。。。
是关于openOffice的,xiaojun207/openoffice4-daemon 这个镜像,我本地pull后构建不了
在构建到安装 X Window System的时候报了这个:
想请问你有遇到这个情况吗?