
最近补习了一下java爬虫的知识,看的是网上找的黑马就业班的视频。刚看完HttpClient和Jsoup的使用,有个练习的案例,由于是几年前的视频了,京东的页面也有了点小小的变化,在此处记录一下。
遇到的问题与解决办法
先分享两个遇到的问题和对应的解决办法
爬取为null的解决办法
此处代码其实都是基本操作,但是如果只是按着视频里面的写,最后会发现没有爬下来数据,都是null。如果打断点debug一下,就能发现原因。如下图
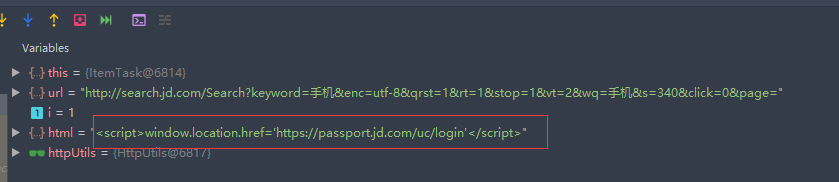
看到这段代码应该就明白了吧,就是京东发现并非人为操作,需要登陆账号了。解决办法也很简单,只需要自己在浏览器登陆之后,把cookies复制下来,在代码中手动设置一下请求头的cookies就可以了。两个方法中的HTTPGet对象都需要设置一下。
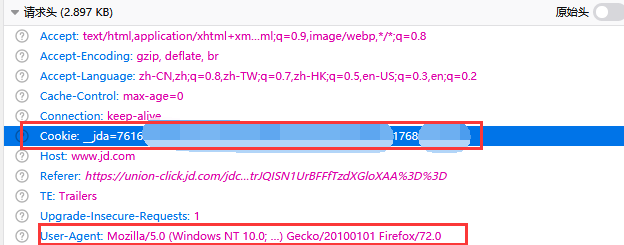
//设置请求头模拟浏览器
httpGet.setHeader("User-Agent","Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:72.0) Gecko/20100101 Firefox/72.0");
httpGet.addHeader("Cookie", "__jda=122xxxxxxxx");User-Agent是浏览器的表示,表示伪装成火狐浏览器请求;cookies是很长的那段字符,上述代码中只截取了一部分
java.lang.IllegalArgumentException: Expected scheme-specific part at index 6: https异常
遇到异常的原因,可以通过日志或者直接把图片链接在请求之前,先把图片链接打印出来。你就会发现报异常之前的那个商品的图片链接没有怕去到,但是直接就去请求一个空链接去下载图片,所以会报异常。
解决办法就是分析这个出现异常的图片,在页面HTML中与其他图片有什么不同。
这张图片的链接属性名是不同的。大部分图片都是data-lazy-img,而这个是data-lazy-img-slave,只需要在按照 data-lazy-img 爬取之后判断一下,如果为空,再按照 data-lazy-img-slave 读取一下属性值就可以。
//商品图片
String picUrlStr = skuEle.attr("data-lazy-img");
if (picUrlStr == null || "".equals(picUrlStr)) {
//部分商品图片规则不一样
picUrlStr = skuEle.attr("data-lazy-img-slave");
}
String picUrl = "https:" + picUrlStr;
picUrl = picUrl.replace("/n9/", "/n1/");
item.setPic(httpUtils.doGetImage(picUrl));数据库
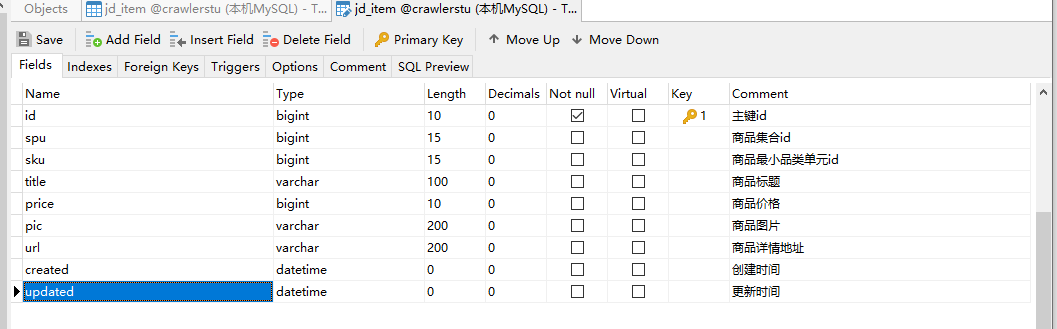
数据库的表结构与视频案例中的是一样的,没有改。
项目代码
项目基本搭建
项目采用的是springboot+Mybatis框架。视频中用的是Jpa,因为我对Mybatis更熟悉一些,所以我就选用了Mybatis操作数据库。其他的连接池、数据库驱动之类的依赖就不多说了,只是一个初级的案例,用的是HttpClient和Jsoup建立连接与解析页面。
关于实体类与Mapper、Service接口的创建,我就直接用的EaseCode(一个IDEA的插件,可以快速根据模板创建代码)一键创建的,略作修改。因为案例中操作数据库只需要两个方法,一个是把实体类保存到数据库,一个是根据实体类条件查询对象集合。
HttpUtils
新建了一个工具类,用于操作HttpClient。并提供了两个方法。
- String doGetHtml(String url); 根据请求的地址,返回页面数据(即返回页面的HTML)
- String doGetImage(String url); 根据传入的图片链接,下载图片并返回生成的图片的文件名
ItenTask
定时爬取页面。具体代码就不在这贴出了,在最下方会把我的练习代码放到GitHub上分享出来。
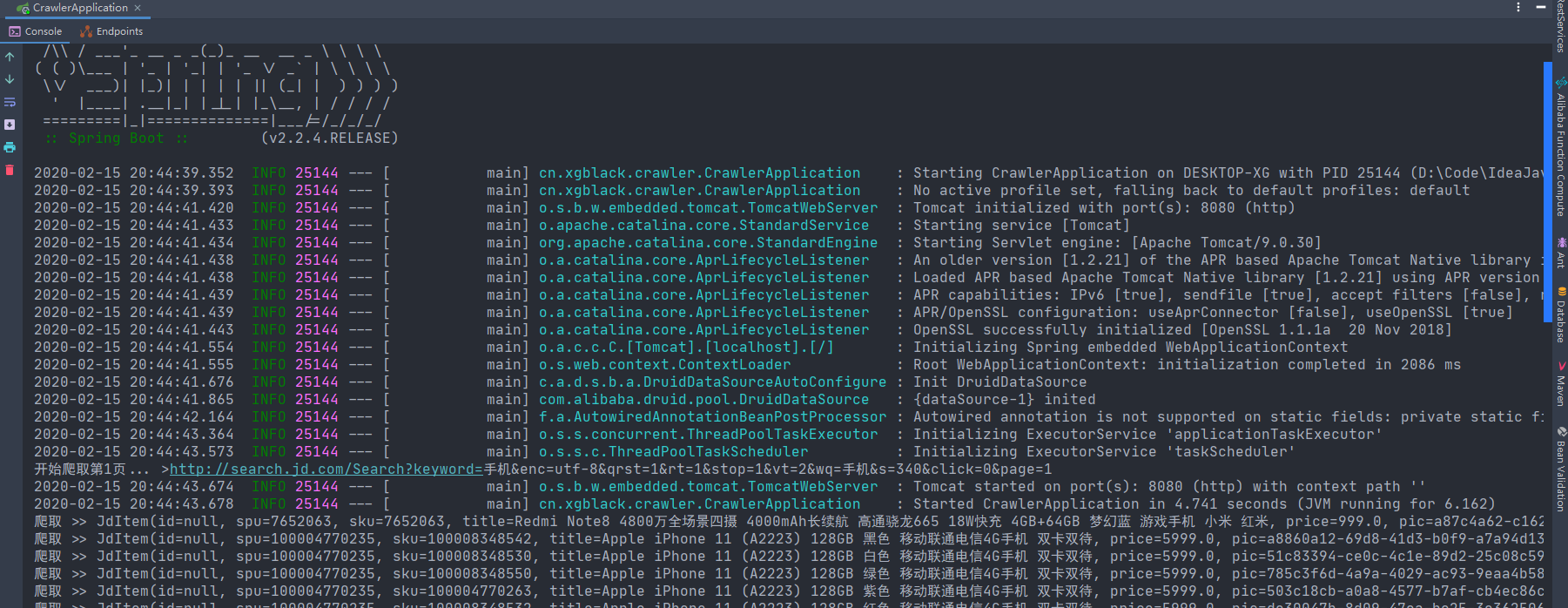
成果


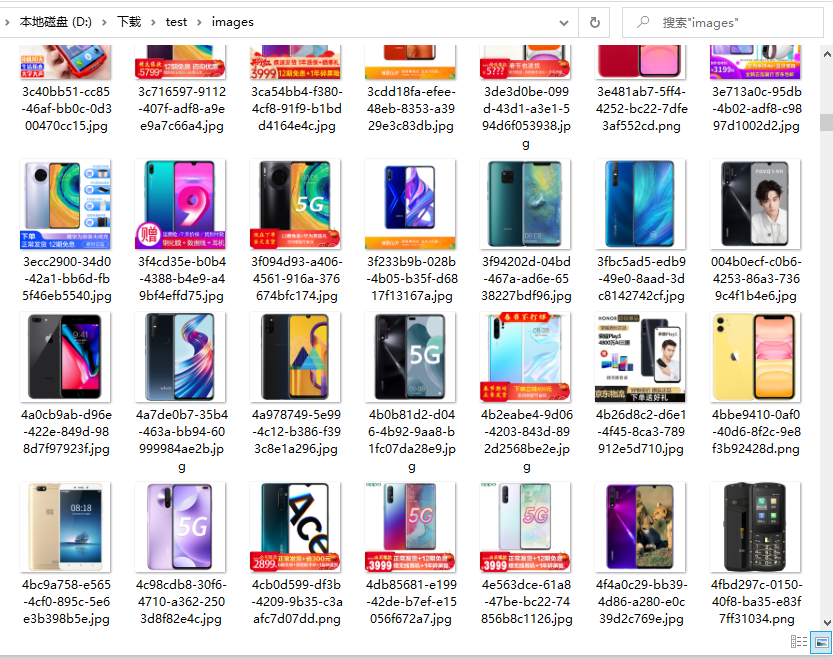
















































有没有关于jd这个爬虫的源码
有,你访问https://github.com/xgblack/java-crawler-study ,里面的crawler-jd就是这个jd的爬虫
主要是解决了我的疑问 回帖感谢